Why KV caching is hard to justify today
KV cache is necessary during inference. Without it, the model recomputes attention over the full context at every token. But keeping it around after the request is a different question. You pay in memory, complexity, and operational surface area. Evaluated in isolation, long-lived KV caching often does not pass a cost-benefit test.
The single-request latency savings are bounded
In one of our Qwen3-30B-A3B experiments, a 1K input / 512 output request had roughly 135 ms TTFT and about 2.5 seconds of total request latency. TTFT includes scheduling and queuing overhead beyond raw prefill compute. If we estimate the prefill compute portion as roughly 100 ms of that 135 ms, eliminating it saves about 4% of total request latency. This is an upper bound on what you would save with a 100% KV cache hit rate.
At 16K input / 512 output, the math gets more interesting, but the conclusion does not change fundamentally. TTFT was about 769 ms out of 3,200 ms total request latency. The upper bound here of prefill time is 24%. That is materially better than the 1K case, but the important variable is not just context length. It is the input/output ratio. KV cache is most effective when the request has a large amount of input context and a relatively small amount of output generation. In that shape of workload, prefill is a larger share of the bill. In a short-input, long-output workload, decode dominates and KV cache has less room to help.
This is why Anthropic can give a large discount for cache hits: cached input tokens are not economically equivalent to fresh input tokens that have to be prefilled again.
But even in the favorable long-input case, a perfect cache hit does not give you a 10x faster request. It saves the prefill slice.
A 4% or 24% slice may look modest in isolation, but production systems run at higher load and higher concurrency. Latency is measured at a target throughput. GPU capacity is scarce. As throughput rises, utilization, queueing, and pipeline stalls amplify the cost of repeated prefill work. The same slice that looks uninspiring on one request can become a meaningful capacity and tail-latency problem when thousands of requests are competing for the same accelerators.
The skepticism is warranted for the single-request case. If the only question is whether a cache hit meaningfully reduces one request's latency, the answer is often no. It depends on the input/output ratio and the prefill cost relative to total request time. KV caching should not be treated as an automatic win at this level of analysis.
It is the input/output ratio, not just the context length, that determines the effectiveness of KV cache.
That said, high input/output ratios are increasingly common. Agentic workloads are multi-turn by nature: context grows over time as chat history, tool call results, and retrieval chunks accumulate. Each subsequent turn has a larger input relative to its output. This is the shape of workload where prefill is an increasingly large share of the bill, and where KV cache reuse has the most room to help.
This matters to both sides of the inference equation. For developers and application teams, KV cache reuse translates directly to lower TTFT, better p95 latency, and lower cost per request. For providers and internal platform teams running GPUs, it translates to higher GPU utilization and more capacity per dollar spent. The same lever -- avoiding repeated prefill -- improves both simultaneously.
Memory is expensive, and KV cache is enormous
Keeping it in GPU memory competes with active inference. Keeping it in host memory is cheaper, but still bounded, and DRAM prices are moving in the wrong direction. Keeping it in remote memory or storage adds transfer latency, placement problems, and operational complexity. KV caching is not free infrastructure. It is a bet. You are spending scarce memory or storage on the hope that future requests will reuse the same work.
Prefix-based KV caching has a narrow sharing model
Most production-friendly KV caching today is prefix caching. If a future request starts with the exact same prefix, the engine can reuse the precomputed KV cache for that prefix. The sharing model is strict: exact prefix match or nothing. Workloads with variable-position shared content (reordered retrieval chunks, varying tool results, shifting user context) can share semantic material without sharing an exact prefix, which limits effective hit rates. The prefix caching internals post explores this limitation in detail with worked examples.
The case against KV caching today: the single-node latency win is bounded, the memory cost is high, and the reuse model is narrow. If you evaluate it as an isolated optimization on a single node, the obvious question is: is all this complexity really worth it? In isolation, often no. But isolation is the wrong frame.
Inference is becoming a distributed systems problem
Prefill and decode are fundamentally different workloads. Prefill is compute-heavy. Decode is memory-bandwidth-sensitive and latency-sensitive. Colocating both on the same accelerator forces a compromise. Disaggregating them creates a natural boundary, and KV cache is the object that crosses it.
KV cache transitions from an inference implementation detail to a first-class distributed systems primitive the moment prefill and decode live on different hardware.
The disaggregation post covers this argument in detail: why the split matters, how NVIDIA Dynamo and AWS/Cerebras are building it into infrastructure, and what it means for KV cache transfer, placement, and lifecycle management.
The economics are starting to move
The second change is that KV cache itself is getting cheaper to store and move. A lot of recent model advancement is really KV cache innovation. The progress over the last 18 months has been striking.
DeepSeek-V2/V3: Multi-head Latent Attention (MLA). MLA compresses keys and values into a shared low-rank latent vector before caching. For DeepSeek-V3, this reduces the per-token cache from roughly 16,384 scalar dimensions (standard multi-head attention) down to 576 (a 512-dimensional latent plus 64 dimensions for decoupled RoPE). Against an MHA baseline, that is a ~28x reduction. Against the GQA baseline most modern models already use, the effective reduction is smaller (roughly 4-8x depending on group size), but MLA achieves this while maintaining MHA-level quality, which GQA trades off.
DeepSeek-V4. V4 combines multiple techniques: Compressed Sparse Attention (CSA) merges every 4 tokens into one entry with overlapping neighborhoods, Heavily Compressed Attention (HCA) consolidates at even wider strides, and sparse top-k selection limits which compressed entries each query attends to. Together with MLA and aggressive quantization, V4's full attention stack requires roughly 2% of the KV cache compared to GQA-8 in BF16. The 2% figure reflects the compound effect of all these techniques together. This is what makes 1M-token contexts practical.
Qwen 3.5: Gated DeltaNet hybrid architecture. Qwen 3.5 replaces 75% of its attention layers with Gated DeltaNet linear attention. These layers maintain a fixed-size state matrix (128 x 128 per head) that gets updated incrementally with each token. The state does not grow with sequence length. Only the remaining 25% of layers (full softmax attention with GQA) require a traditional KV cache. At long context lengths (where KV cache dominates memory), this effectively eliminates most of the KV cache growth. The savings are proportional to context length: at 256K tokens the reduction is substantial, at 1K tokens it is modest because the fixed-size state cost is comparable to a small KV cache.
Gemma 4: sliding window + unified KV. Gemma 4 interleaves local sliding-window attention (512 or 1024 tokens depending on model size) with sparse global attention layers. Most layers only cache the window, not the full sequence. Global layers use unified keys and values (shared KV heads) with Proportional RoPE to handle long contexts without proportional memory growth.
TurboQuant/PolarQuant (Google, ICLR 2026). A different angle: instead of changing the attention mechanism, quantize the KV cache itself to 3-4 bits per coordinate with no measurable accuracy loss on standard benchmarks. PolarQuant rotates vectors with a random orthogonal matrix so coordinates follow a known distribution, then applies an optimal Lloyd-Max scalar quantizer. QJL adds a 1-bit residual correction. At 4 bits, the paper reports up to 8x faster attention on H100. At 3 bits, roughly 6x memory reduction. No model changes or retraining required. This works with any existing model.
The direction is clear even if the exact numbers depend on baselines and configurations. MLA reduced KV cache by an order of magnitude against MHA. CSA reduced it further with aggressive token compression. Gated DeltaNet eliminates KV cache growth for most layers entirely. TurboQuant offers 6x as a drop-in that works with any existing model. Each approach makes a different tradeoff, but they all shrink the same object.
That matters because memory cost is the common objection to KV caching. If the cache shrinks by 6x to an order of magnitude or more, the break-even calculation changes. More entries fit in the same budget. Transfers from remote memory, SSD, or another node become faster. The cache does not need to become trivially small. It just needs to become small enough that the economics cross over for the workloads people actually run.
The storage hierarchy is changing too. Historically, it was easy to say, "If the KV cache is not in GPU memory, it is too slow to matter." That is becoming less obviously true. High-bandwidth interconnects and fast local NVMe are changing the tradeoff. The relevant comparison is broader than "can I move the KV cache faster than I can recompute it?" The better question is whether moving or loading the KV cache can relieve the decode GPU from repeated prefill work and let it stay focused on the latency-sensitive part of the pipeline. If storage-backed KV cache reduces prefill pressure, avoids stalls, and keeps scarce accelerator capacity pointed at decode, then it can make sense even when the request-level savings look modest.
The answer depends on the specific workload. For a given model and context length, the system has to compare the time to recompute prefill, the time to transfer KV cache over the network, the time to read KV cache from SSD, the cost of reserving memory or storage for that cache, and the probability that the cache will be reused. If transfer or load time is materially lower than recompute time, and reuse probability is high enough, the cache is useful. If not, the cache is a cost without a return.
This is also why production load matters so much. The benefit is not just the milliseconds saved on a single request. It is the prefill work that does not need to be scheduled at peak load. It is the GPU capacity that stays available for decode. It is the queue that does not grow. It is the stall that does not ripple through the pipeline. In a saturated system, capacity and latency are inseparable. Improving useful throughput is often the most reliable way to improve tail latency.
Not every workload needs fast prefill
There is a growing class of agentic workloads that run on a schedule rather than in response to a user waiting for a reply. Background agents, periodic summarization, proactive monitoring, scheduled code analysis -- these are not latency-sensitive. They do not need to compete for the fastest prefill path. For these workloads, off-the-shelf prefill without KV cache reuse makes sense. They can trade latency tolerance for cost, throughput, and cache-resource budget. Letting background work absorb full prefill cost means the KV cache resources stay available for the workloads that actually need low TTFT: interactive agents, real-time assistants, user-facing applications. This is a scheduling distinction, not a caching one. But it matters for capacity planning because it determines which workloads should consume scarce cache resources and which should not.
What prefix caching looks like under load
We can see this directly in a simple prefix caching experiment with Qwen3-1.7B on an L40S. The setup uses a 10K-token prompt and varies the number of common prefix tokens from 0 to 10K across different concurrency levels. As expected, the vLLM prefix cache hit ratio rises from 0 to 1 as the shared prefix grows. That is the controlled variable. The dependent variables are throughput and request latency at different concurrency levels.
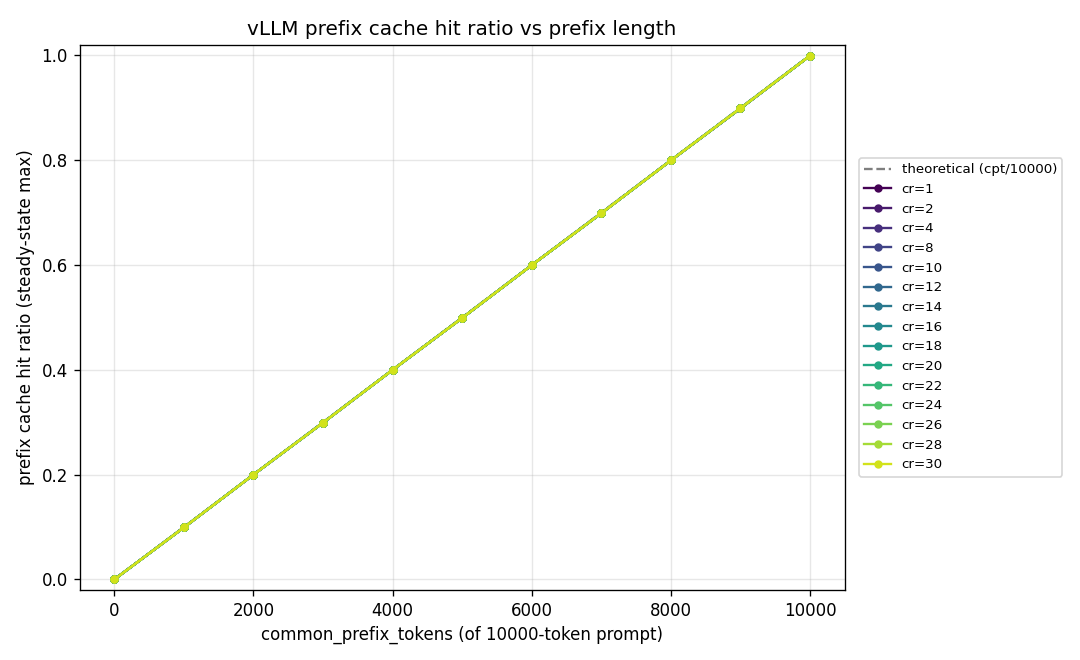
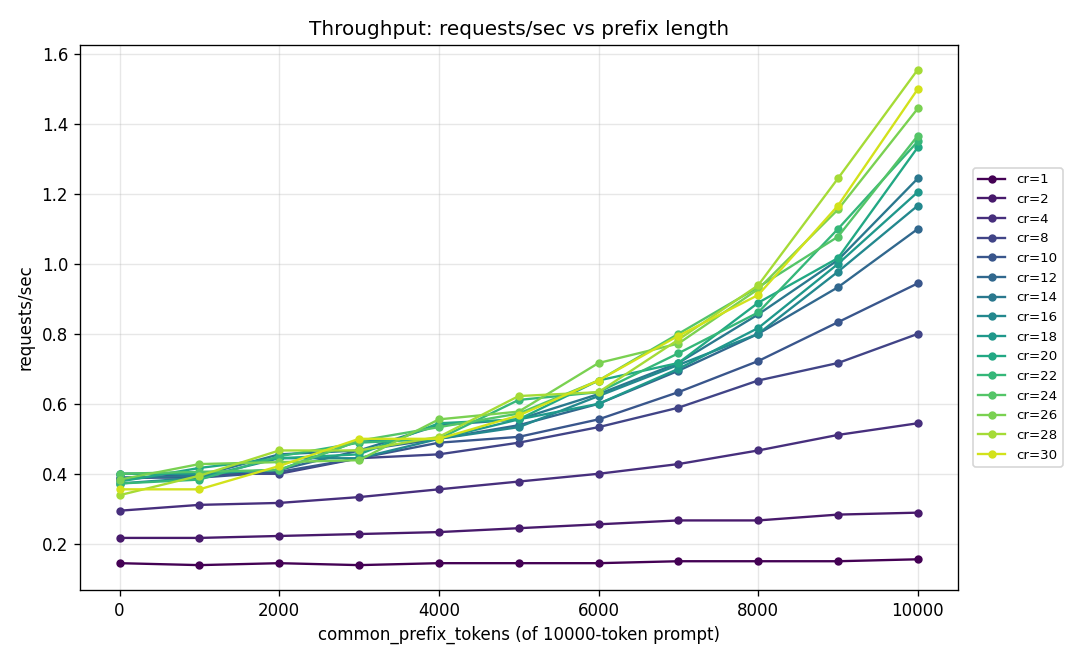
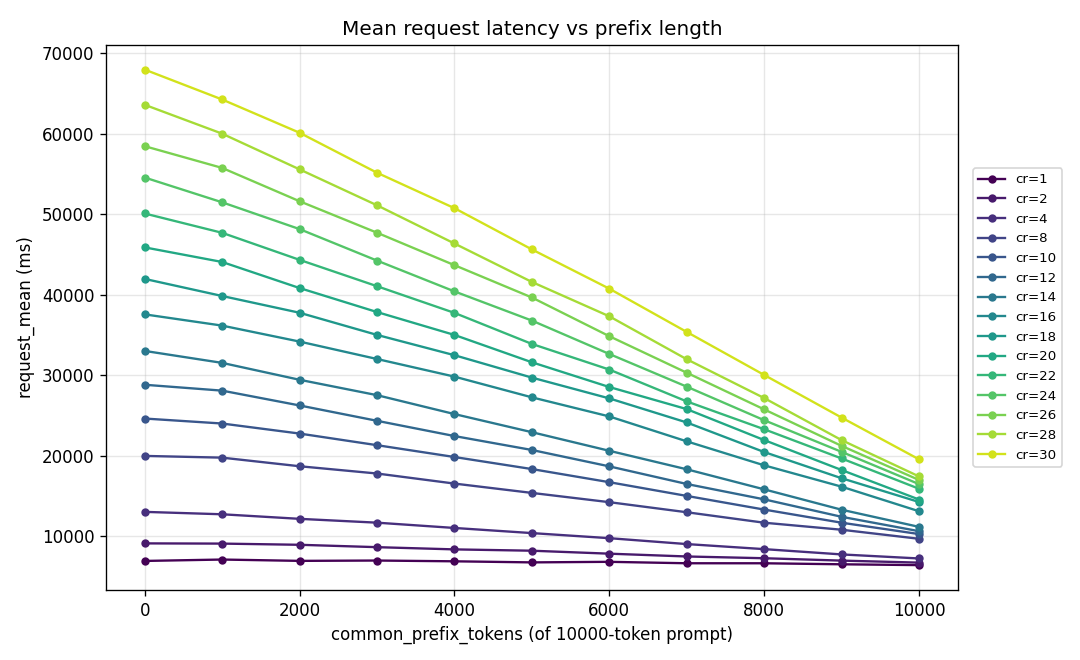
At low concurrency, increasing the prefix cache hit ratio helps, but the improvement is modest. At higher concurrency, the same increase in cache hit ratio produces a much larger system effect. Requests per second climbs sharply as more of the prompt is served from cache. Mean request latency moves in the opposite direction, falling fastest at the higher concurrency levels. This is the shape you would expect if KV caching is primarily a systems optimization rather than a single-request latency trick.
The cache hit removes repeated prefill work from the hot path. That frees accelerator capacity, reduces interference, and changes the latency curve at the throughput levels where production systems actually run. This is why the single-request framing is misleading. A cache hit may only save a bounded slice of one request, but at concurrency it changes the operating point of the system.
This experiment uses a small model on a single node, which does not validate the disaggregated architecture argument directly. But it does demonstrate the mechanism: prefix cache hits remove prefill work from the serving path, and the system-level benefit scales with concurrency. The disaggregation thesis is that this same mechanism becomes even more powerful when prefill and decode run on separate hardware and the KV cache moves between them as a first-class object.
Prefix caching already works for the right workloads
Prefix caching has a narrow sharing model for general-purpose workloads. For agentic workflows, it fits naturally -- but the justification varies by context category.
System prompts are the easy case. They are stable across requests, sit at the front of the prompt, and are a textbook prefix cache hit. An agent making a series of tool calls against the same backend reuses the same 2K-8K token system prompt on every request. Multi-turn conversations with a fixed system prompt reuse the entire instruction block. Code generation agents with stable repository context reuse the project description and file summaries. For this category, cross-request KV caching is straightforward.
Other categories of context require more nuance. Chat history grows and shifts between turns. Tool call exemplars may be reordered or swapped. Retrieval chunks change per query. These elements often share material across requests without sharing an exact prefix. Whether KV cache helps depends on how much of the context is positionally stable (benefiting from prefix caching) versus variable (requiring techniques like CacheBlend to unlock reuse). The system prompt case is clear. The rest of the context is where the harder engineering problems live.
Anthropic's prompt caching, OpenAI's cached tokens, and vLLM's automatic prefix caching all exist because agent-shaped workloads generate high prefix reuse rates without any special effort from the developer. The charts above show the throughput and latency response when reuse is high. For agentic workloads, it frequently is. (For a deeper look at how vLLM and SGLang implement prefix caching under the hood, see the companion post on prefix caching internals.)
Beyond exact prefixes: an active area of research
The limitation shows up in messier patterns. RAG with variable retrieval chunks. Tool results that differ between calls. User-specific context that shifts position in the prompt. Two requests may share a lot of material without sharing the exact same prefix. Classic prefix caching returns a miss in those cases even when most of the computation could have been reused.
CacheBlend is one research direction exploring this space. The idea that interests me most is not full cache blending per se, but the narrower problem of cache repair: given a KV cache that is close-but-not-exact to what the current request needs, selectively recompute only the parts that differ. If you can repair a cached entry cheaply, individual KV caches become more reusable across requests, and cache hit rates go up without requiring more memory. That would make limited cache budgets go further.
This is still an open research problem, not a solved one. No major inference framework ships chunk-level KV reuse today. The selective recomputation adds its own latency, quality preservation depends on workload characteristics, and the evaluation methodology for measuring these tradeoffs is still maturing. But the direction is promising: making cached entries more flexible increases the effective hit rate within the same memory budget.
Prefix caching already answers "does caching work?" for a growing class of workloads. The open question is "how much of the remaining workload can we bring into the cacheable regime?" Cache repair and related techniques are where that question gets explored.
The system-level argument
The direct single-request latency win is bounded by the prefill slice. The stronger argument is about the serving system as a whole.
A cache miss is work that competes for decode capacity. A cache hit removes that competition. It lets decode nodes stay focused on the latency-sensitive phase instead of being interrupted by repeated prefill.
That distinction compounds under load. Fewer repeated prefills means less interference, better decode throughput, higher goodput, and less queueing pressure. That is where latency improves. Not because caching is a shortcut, but because the serving system spends less time repeating work that could have been stored.
This is the part that gets lost when KV caching is discussed only as a request-level latency optimization. At low throughput, a 4% prefill slice looks like a rounding error. At high throughput, that same work competes for scarce GPU capacity and can worsen the latency curve for everyone behind it. Pipeline stalls are not evenly distributed. They show up as tail latency, missed SLOs, and lower effective capacity.
From per-request state to systems primitive
KV caching does not make much sense if you evaluate it as an isolated optimization on a single node. The single-request latency savings are bounded. The memory cost is high. Prefix-based reuse is limited. That critique is real.
But inference architecture is moving. Disaggregated prefill and decode creates the right interface. Better attention mechanisms reduce the size of the object we need to store and move. Faster networks and SSDs improve the transfer math. Cache repair techniques could improve reuse beyond strict prefixes. Rising DRAM costs and scarce GPU capacity make waste harder to ignore.
That combination changes KV cache from a temporary intermediate state into an inference systems primitive. The goal is to optimize the serving system, and KV caching is one of the levers for doing so.
The objective is to maximize useful throughput and protect decode latency. KV caching is one mechanism for achieving that. Its value is proportional to the prefill work it displaces, the reuse rate it achieves, and the cost of the infrastructure required to support it.